Summary
We present an efficient video generation framework based on latent diffusion models, termed as MagicVideo. Given a text description, MagicVideo is able to generate photo-realistic video clips with high relevance to the text content. Different from recent diffusion model based video generation framework that uses cascaded super-resolution pipeline, MagicVideo is able to generate high resolution video frames with single model inference. To make the best use of the prior knowledge from text-to-image generation tasks, we keep most of the convolution operator in 2D space and introduce a unique adaptor for each 2D convolution to learn the frame specific features. The temporal information is learned via a novel directed temporal attention module. It is used to capture the relation among frames and generate temporally meaningful sequence of frames. The whole gen- eration process is within the low dimension latent space of a pre-trained variation auto-encoder. This practice speeds up the training of the video generation model significantly and reduce the sampling time by 80×, compared to traditional DDPM based video diffusion models. We demonstrate that MagicVideo can generate high spatial resolution video clips in a single step without the cascade diffusion pipeline. Mag- icVideo is able to generate both realistic video content and imaginary content in a photo-realistic style with state-of- the-art trade-off in terms of quality and computational cost.
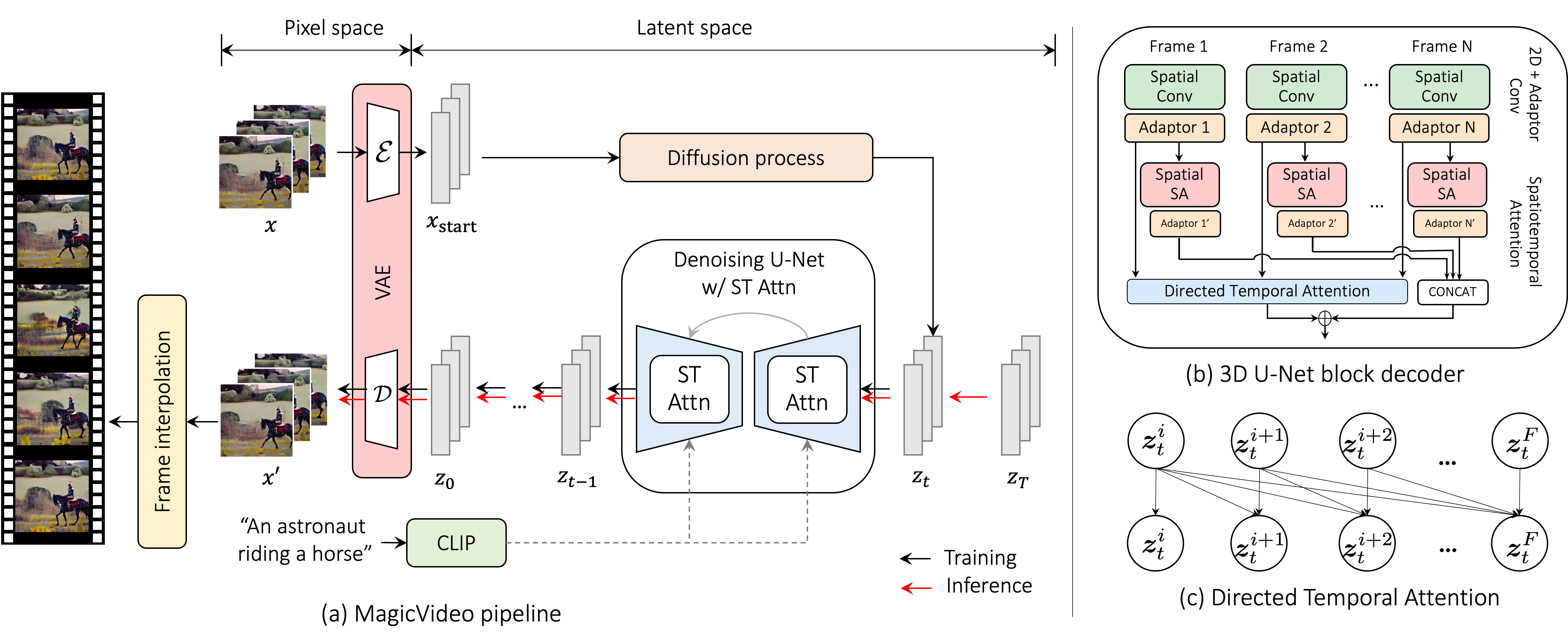
The framework includes three
steps: keyframe generation, frame interpolation, and super-resolution. For the keyframe generation, we first present
how we modify the 2D convolution blocks with weights
pre-trained on the text-image dataset to adapt to the 3D
video dataset via a new adaptor module (Sec. 3.2.1). Then,
we show a novel directed self-attention module that enables
the model to learn the motions among frames within a video
clip (Sec. 3.2.2). In Sec. 3.3, we show how we interpo-
late the frames to make the generated smoothing. Finally,
we explain how to increase the spatial resolution via a sepa-
rately trained super-resolution model as detailed in Sec. 3.4.
Fig. 3 illustrates the whole pipeline.